














In our recent SNIA Data, Storage & Networking webinar, “AI Model Inferencing and Deployment Options,” our expert presenters explained the process of model inferencing, discussed how trained models are used to make predictions, and offered considerations for deploying models. The live inferencing demo brought all the concepts presented earlier to life.
If you missed the live session, you can view it here in the SNIA Educational Library along with a PDF of the webinar slides. Our live audience asked quite a few intriguing questions. Here are our presenters’ answers.
Q: Why are inference and serving 2 different steps? How are they different from each other?
A: Inference is the act of using the trained model to make a prediction on new data. Serving is the process of hosting and managing the trained model
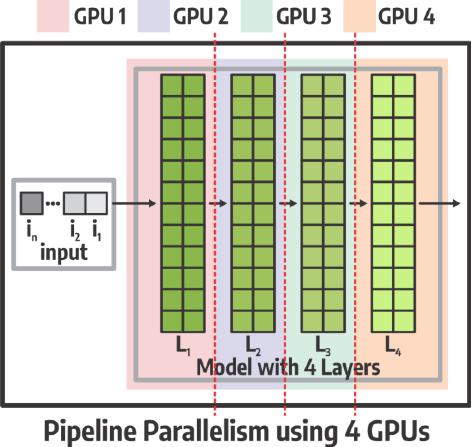
Q: In TP (model split horizontally), are the layers split sequentially (say 8 layer model) split into 4 layers on GPU1 and 4 layers on GP2, and in PP (model split horizontally) are the layers split in a way where even number layers (2,4,6,8) on GPU1 and odd number layers (1,3,5,7) on GPU2?
A: In PP the model layers are distributed across the GPUs, generally sequentially. In an example 4 layer model, layer 1 is on GPU1, layer 2 is on GPU 2 ….. Layer 4 is on GPU 4.In an example 8 layer model, layers 1&2 are on GPU1, layers 3&4 are on GPU 2 ….. Layers 7&8 are on GPU 4.
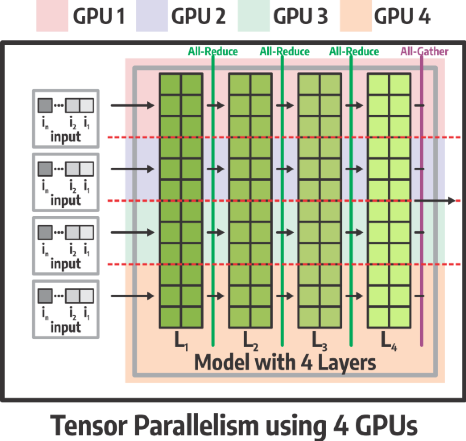
For TP, parts of each layer run on each GPU, and the results from each layer are recombined using communication collectives (All-reduce) to continue.
As you see below, each GPU implements part of each layer.
Q: You have some listeners from the storage sector. Can you characterize the I/O needs of inferencing and contrast them with LLM training I/O?
A: Training is often data-pipeline-bound, requiring a high-bandwidth, reliable storage and networking system to feed massive amounts of data to the compute cluster without bottlenecks. Inference requires moving and loading model weights and KV-cache data and is primarily memory bandwidth-bound. The core inference process requires minimal disk storage I/O. The second link below goes into KV-cache offloading to storage for this. Secondarily, there is a whole other topic of storage needs when it comes to AI applications that use Inferencing, such as RAG, and agentic AI, where model context is sourced from external sources such as NFS, and other enterprise data sources (DB, SharePoint, Confluence, etc.), where storage and storage performance may come into play.
We suggest watching the following SNIA webinars:
Q: Can we have the vLLM demo scripts made available through a GitHub repo, along with detailed steps on how to set up the environment locally (assuming we have a GPU server), build, and execute the scripts?
A: Unfortunately, as it is an internal tool, it cannot be shared at this time, but most of the commands that were run can also be replicated with AIperf (GitHub - ai-dynamo/aiperf).
For the inferencing environment used, following Using Docker - vLLM provides containers to get started.
Q: How is the probability of End-of-Sequence (EoS) token calculated?
A: No different than any other token from the model perspective. It is just another token, the end token. The model may also terminate a sequence for other reasons, such as hitting the max_tokens limit set in the prompt parameters, reaching its total context capacity for the model, or if a safety mechanism is triggered.
Q: Are you using the same 14B model for all the graphs on slide #34?
A: No, that was just a slide that I grabbed from some tests I did a while ago to illustrate the point that with TP, don’t expect a linear scale, and in many cases, doing DP may result in a better result depending on the load.
This webinar is part of the SNIA Data, Storage & Networking “AI Stack” webinar series. We encourage you to register for upcoming sessions and view past presentations on demand.
- On-Demand: Introduction to AI and Machine Learning
- On-Demand: AI Model Inferencing and Deployment Options
- December 10, 2025: From Data to Decisions: Understanding How AI Models Learn
- January 29, 2026: Accelerating AI Infrastructure: The Role of 400G and PCIe 8.0 in Next-Gen Interconnects
- February 4, 2026: AI Meets Storage: Comparing On-Prem, Cloud, and Hybrid Architectures Across the AI Lifecycle
We have many more webinars planned for the new year. Follow us on LinkedIn, X, and the SNIA Blog for upcoming dates and topics.
Leave a Reply