














This blog post was written based on content presented at the session HDD Innovations for Hyperscale at SDC 2025. You can watch the full video on the SNIAVideo YouTube Channel at this link.
For all the noise around solid-state storage, hyperscale data centers continue to rely heavily on nearline hard-disks (HDDs) for capacity-optimized workloads. That reliance is not slowing down. If anything, the stakes for innovation in hard drives are rising as fast as the data itself.
At the SNIA Developer Conference (SDC) 2025, we walked through why capacity HDDs remain essential, and why the industry is investing deeply in technologies like shingled magnetic recording (SMR), head depopulation (DEPOP), and command duration limits (CDL). Here’s a closer look at what’s driving these developments and how the ecosystem is maturing around them.
Hyperscale Demand Is Still Climbing
The forecasts tell a clear story: HDDs aren’t going anywhere.
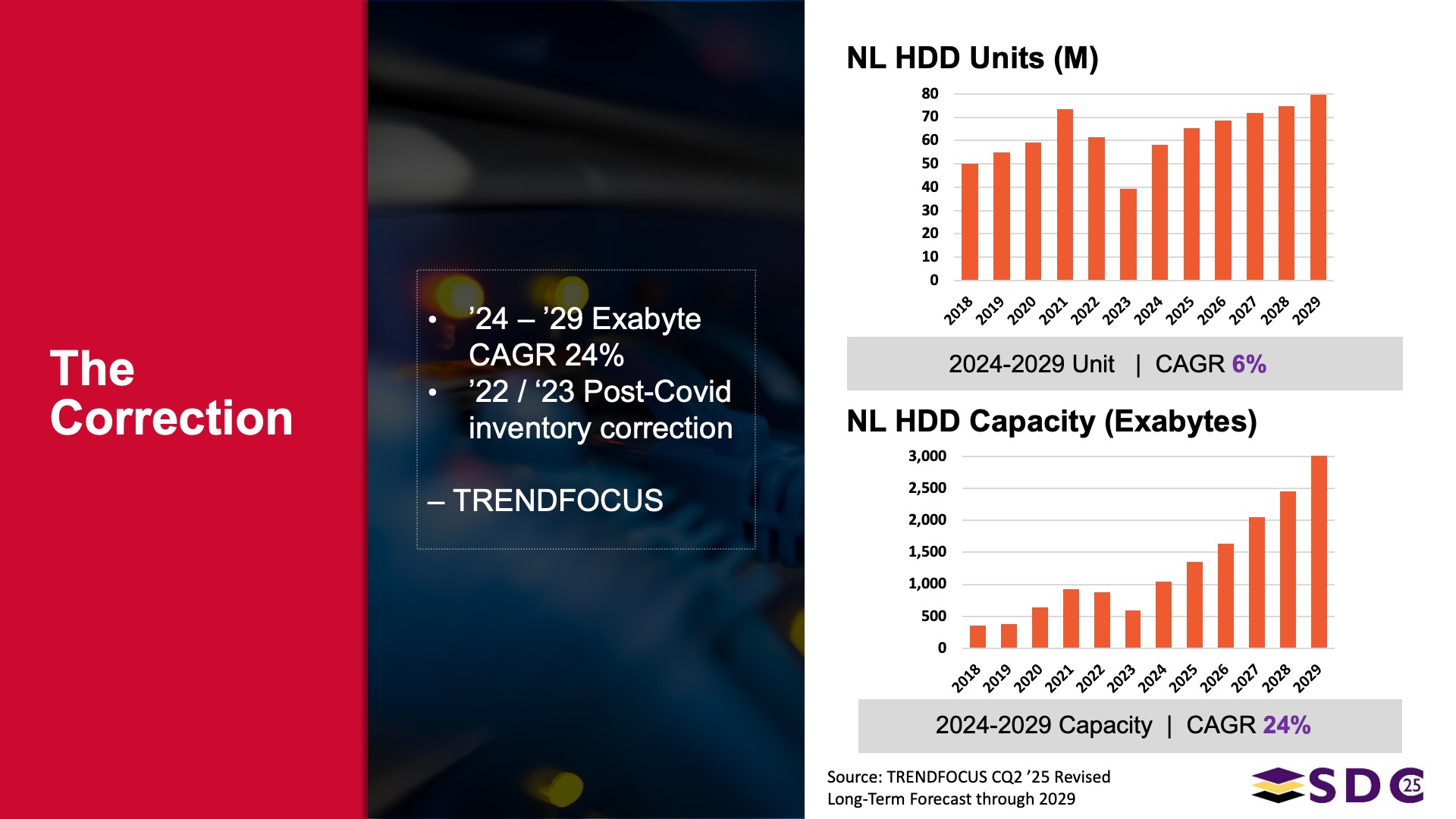
TRENDFOCUS nearline data shows:
- 6% unit CAGR through the end of the decade
- 24%+ capacity CAGR, driven by SMR and emerging technologies like HAMR
- Tier-1 cloud service providers expected to consume 1000+ exabytes of nearline HDD capacity in 2025 alone
For comparison, all NAND manufacturing capacity (QLC, TLC, enterprise, consumer, everything) adds up to less than 1000 exabytes. Even if QLC pricing fell dramatically, we are nowhere near the crossover point. Hyperscalers generally need a 2–3× cost delta before shifting capacity to QLC en masse, and today that gap remains 5–8×.
HDDs continue to offer the lowest cost-per-terabyte at scale, which means the industry has every reason to push their capabilities further.
SMR Is Entering a New Phase of Adoption
Shingled Magnetic Recording (SMR) is not new. The first hyperscale deployments started in 2013–2014. However, its ecosystem maturity has drastically improved.
SMR works by overlapping tracks (“shingling”) to increase areal density and drive capacity. Reads behave normally but writes must be sequential at the zone level. That write constraint was historically the barrier to widespread adoption.
Today, that barrier is falling fast.
A modern SMR stack now exists:
- Kernel support since Linux 4.10
- A major scheduler/coordination rewrite in Linux 6.10
- Mature support in Device Mapper, including DM-crypt
- Full filesystem support in Btrfs and now XFS for host-managed SMR
- Robust tools: sg3_utils, util-linux, FIO support, and ecosystem-ready utilities
This means applications can use filesystems instead of custom zone-aware applications—and still get the sequential-write guarantees that SMR requires. The result: significantly simpler deployments options and broader viability for SMR in hyperscale workloads.
DEPOP: Keeping Drives Useful Longer
As HDD capacities grow (30–40 TB and rising), a single head failure on a single platter becomes a major operational event. Historically, the response was simple: pull the drive and rebuild. But with multi-day rebuild times and petabyte-scale systems, that’s now unacceptable.
Depopulation (DEPOP) allows a drive to keep operating even when a head or platter develops issues.
Two flavors exist:
1. Offline DEPOP (logical depopulation)
- Drive goes offline
- Drive is reformatted without the failing head
- Capacity is reduced, but the drive lives on
This aligns with the SCSI SBC-4/SBC-5 specifications and is available today.
2. Data-preserving DEPOP
- No reformat needed
- Only the zones served by the affected head are marked offline
- Particularly useful for SMR, where zones map cleanly to heads
Given that a high percentage of RMA drives turn out to have only a single head failure, DEPOP can materially reduce waste, improve availability, and lower operational churn.
Real-world uptake is beginning now, and broader deployments are coming quickly.
Command Duration Limits: Controlling Tail Latency
Hyperscaler architectures often tolerate some latency variation, but not extreme tail latency. When a single slow read can jeopardize system-wide SLAs, operators cap queue depth to keep I/O predictable. Unfortunately, capping queue depth also caps IOPS.
Command Duration Limits (CDLs) allow HDDs to operate at high queue depths without extreme tail latency.
Here’s how it works:
- Multiple drives receive the same read request
- A policy describes when to accept the first response and gracefully abort the others
- The result: tail latency becomes flatter than the average latency at scale
CDLs originated in the OCP Cloud-Optimized HDD spec in 2018 and entered upstream Linux in kernel 6.5. Tools, test suites, and FIO support are all shipping today.
This technology directly improves IOPS per terabyte, system efficiency, and SLA reliability—exactly what hyperscalers need from high-capacity HDDs.
Open Source and Standards: The Real Story
None of these capabilities (SMR, DEPOP, or CDL) would be useful without deep ecosystem readiness. That means:
- T10/T13 standards for ZBC, ZAC, CDL, DEPOP, and SAT
- Linux block layer integration
- Filesystem and device-mapper support
- User-space libraries
- Vendor firmware and qualification work
- Tools for monitoring, debugging, and performance validation
These are not just theoretical technologies now—they’re practical, testable, deployable, and increasingly visible in production environments.
The Bottom Line
HDDs remain the backbone of hyperscale capacity. And instead of standing still, they’re evolving quickly:
- SMR is finally ecosystem-ready
- DEPOP reduces operational overhead and extends useful drive life
- CDLs unlock higher performance at scale
- Standards and open-source work ensure these technologies work consistently across vendors and platforms
Innovation in HDDs is not slowing down. If anything, it is accelerating, because the need for cheap, dense, dependable storage has never been greater.
To learn more, watch this SDC 2025 presentation, “HDD Innovations for Hyperscale.”
Leave a Reply