








The Fibre Channel (FC) industry introduced Fabric Notifications as a key resiliency mechanism for storage networks in 2021 to combat congestion, link integrity, and delivery errors. Since then, numerous manufacturers of FC SAN solutions have implemented Fabric Notifications and enhanced the overall user experience when deploying FC SANs.
On August 27, 2024, the SNIA Data, Networking & Storage Forum is hosting a live webinar, “The Evolution of Congestion Management in Fibre Channel,” for a deep dive into Fibre Channel congestion management. We’ve convened a stellar, multi-vendor group of Fibre Channel experts with extensive Fibre Channel knowedge and different technology viewpoints to explore the evolution of Fabric Notifications and the available solutions of this exciting new technology. You’ll learn:
- The state of Fabric Notifications as defined by the Fibre Channel standards.
- The mechanisms and techniques for implementing Fabric Notifications.
- The currently available solutions deploying Fabric Notifications.

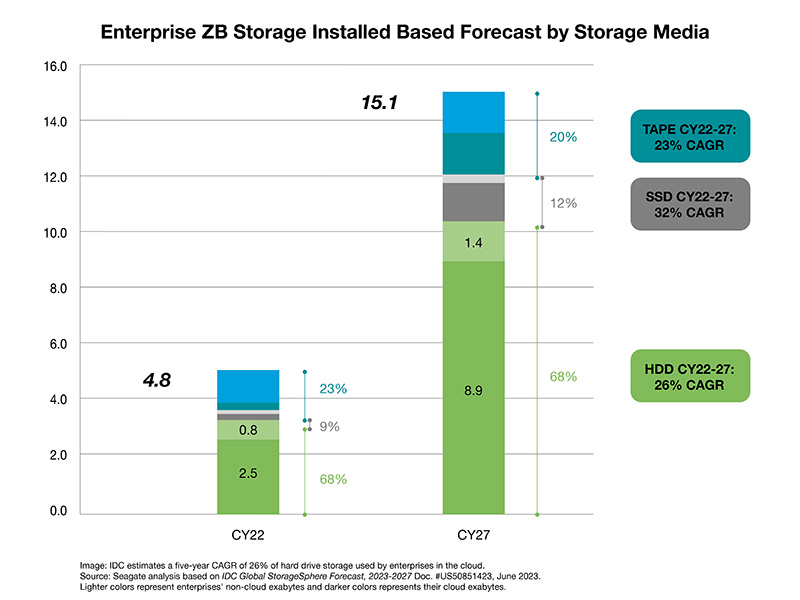 Myth: SSD pricing will soon match the pricing of hard drives.
Truth: SSD and hard drive pricing will not converge at any point in the next decade.
Hard drives hold a firm cost-per-terabyte (TB) advantage over SSDs, which positions them as the unquestionable cornerstone of data center storage infrastructure.
Analysis of research by
Myth: SSD pricing will soon match the pricing of hard drives.
Truth: SSD and hard drive pricing will not converge at any point in the next decade.
Hard drives hold a firm cost-per-terabyte (TB) advantage over SSDs, which positions them as the unquestionable cornerstone of data center storage infrastructure.
Analysis of research by 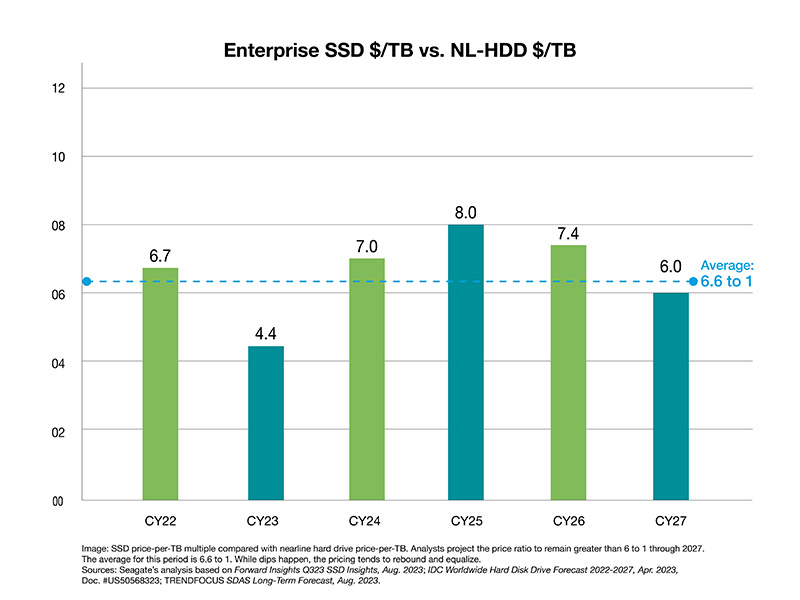 This differential is particularly evident in the data center, where device acquisition cost is by far the dominant component in total cost of ownership (TCO). Taking all storage system costs into consideration—including device acquisition, power, networking, and compute costs—a far superior TCO is rendered by hard drive-based systems on a per-TB basis.
This differential is particularly evident in the data center, where device acquisition cost is by far the dominant component in total cost of ownership (TCO). Taking all storage system costs into consideration—including device acquisition, power, networking, and compute costs—a far superior TCO is rendered by hard drive-based systems on a per-TB basis.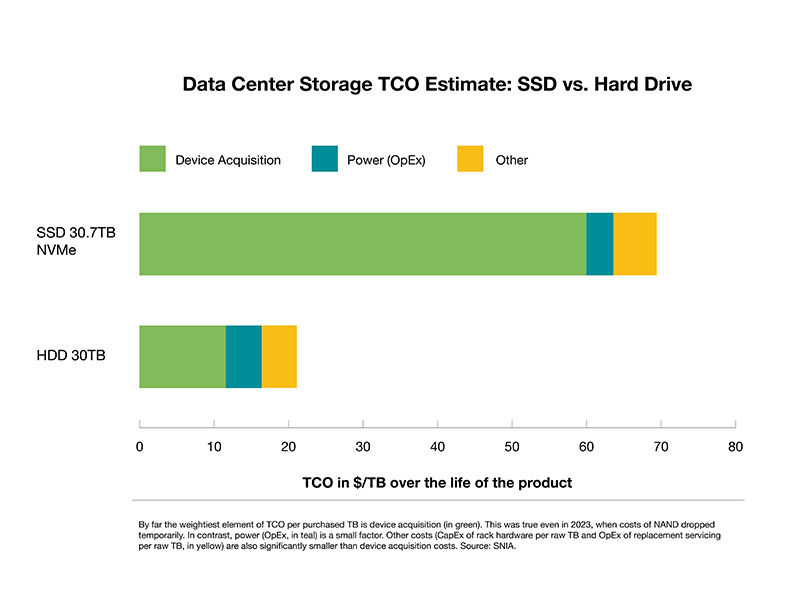 Myth: Supply of NAND can ramp to replace all hard drive capacity.
Truth: Entirely replacing hard drives with NAND would require untenable CapEx investments.
The notion that the NAND industry would or could rapidly increase its supply to replace all hard drive capacity isn’t just optimistic—such an attempt would lead to financial ruin.
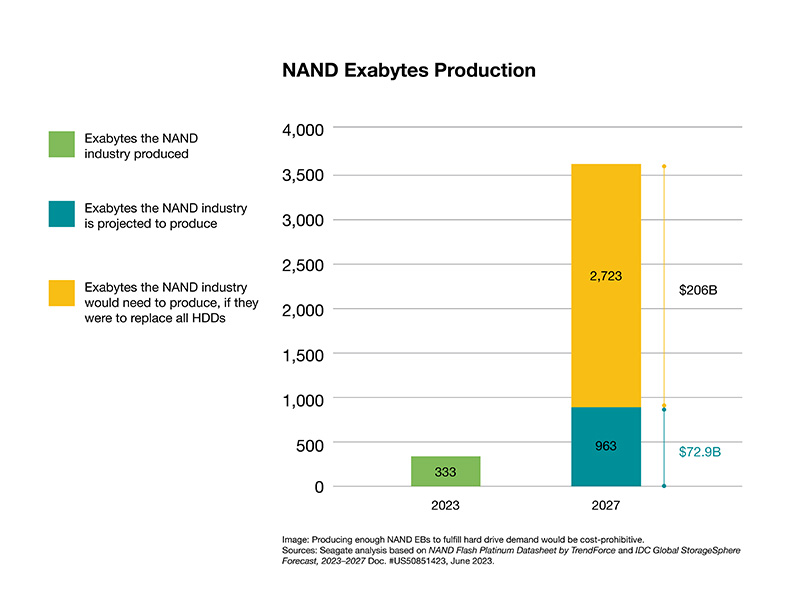
According to the Q4 2023 NAND Market Monitor report from industry analyst Yole Intelligence, the entire NAND industry shipped 3.1 zettabytes (ZB) from 2015 to 2023, while having to invest a staggering $208 billion in CapEx—approximately 47% of their combined revenue.
In contrast, the hard drive industry addresses the vast majority—almost 90%—of large-scale data center storage needs in a highly capital-efficient manner. To help crystalize it, let's do a thought experiment. Note that there are 3 hard drive manufacturers in the world. Let's take one of them, for whom we have the numbers, as an example. Look at the chart below where byte production efficiency of the NAND and hard drive industries are compared, using this hard drive manufacturer as a proxy. You can easily see, even with just one manufacturer represented, that the hard drive industry is far more efficient at delivering ZBs to the data center.
Could the flash industry fully replace the entire hard drive industry’s capacity output by 2028?
Yole Intelligence report cited above indicates that from 2025 to 2027, the NAND industry will invest about $73 billion, which is estimated to yield 963EB of output for enterprise SSDs as well as other NAND products for tablets and phones. This translates to an investment of about $76 per TB of flash storage output. Applying that same capital price per bit, it would require a staggering $206 billion in additional investment to support the 2.723ZB of hard drive capacity forecast to ship in 2027. In total, that’s nearly $279 billion of investment for a total addressable market of approximately $25 billion. A 10:1 loss.
This level of investment is unlikely for an industry facing uncertain returns, especially after losing money throughout 2023.
Myth: Supply of NAND can ramp to replace all hard drive capacity.
Truth: Entirely replacing hard drives with NAND would require untenable CapEx investments.
The notion that the NAND industry would or could rapidly increase its supply to replace all hard drive capacity isn’t just optimistic—such an attempt would lead to financial ruin.
According to the Q4 2023 NAND Market Monitor report from industry analyst Yole Intelligence, the entire NAND industry shipped 3.1 zettabytes (ZB) from 2015 to 2023, while having to invest a staggering $208 billion in CapEx—approximately 47% of their combined revenue.
In contrast, the hard drive industry addresses the vast majority—almost 90%—of large-scale data center storage needs in a highly capital-efficient manner. To help crystalize it, let's do a thought experiment. Note that there are 3 hard drive manufacturers in the world. Let's take one of them, for whom we have the numbers, as an example. Look at the chart below where byte production efficiency of the NAND and hard drive industries are compared, using this hard drive manufacturer as a proxy. You can easily see, even with just one manufacturer represented, that the hard drive industry is far more efficient at delivering ZBs to the data center.
Could the flash industry fully replace the entire hard drive industry’s capacity output by 2028?
Yole Intelligence report cited above indicates that from 2025 to 2027, the NAND industry will invest about $73 billion, which is estimated to yield 963EB of output for enterprise SSDs as well as other NAND products for tablets and phones. This translates to an investment of about $76 per TB of flash storage output. Applying that same capital price per bit, it would require a staggering $206 billion in additional investment to support the 2.723ZB of hard drive capacity forecast to ship in 2027. In total, that’s nearly $279 billion of investment for a total addressable market of approximately $25 billion. A 10:1 loss.
This level of investment is unlikely for an industry facing uncertain returns, especially after losing money throughout 2023.
 Myth: Only AFAs can meet the performance requirements of modern enterprise workloads.
Truth: Enterprise storage architecture usually mixes media types to optimize for the cost, capacity, and performance needs of specific workloads.
At issue here is a false dichotomy. All-flash vendors advise enterprises to “simplify” and “future-proof” by going all-in on flash for high performance. Otherwise, they posit, enterprises risk finding themselves unable to keep pace with the performance demands of modern workloads. This zero-sum logic fails because:
Myth: Only AFAs can meet the performance requirements of modern enterprise workloads.
Truth: Enterprise storage architecture usually mixes media types to optimize for the cost, capacity, and performance needs of specific workloads.
At issue here is a false dichotomy. All-flash vendors advise enterprises to “simplify” and “future-proof” by going all-in on flash for high performance. Otherwise, they posit, enterprises risk finding themselves unable to keep pace with the performance demands of modern workloads. This zero-sum logic fails because:
 In some cases, all-flash systems are not even required at all as part of the highest performance solutions. There are hybrid storage systems that perform as well as or faster than all-flash.
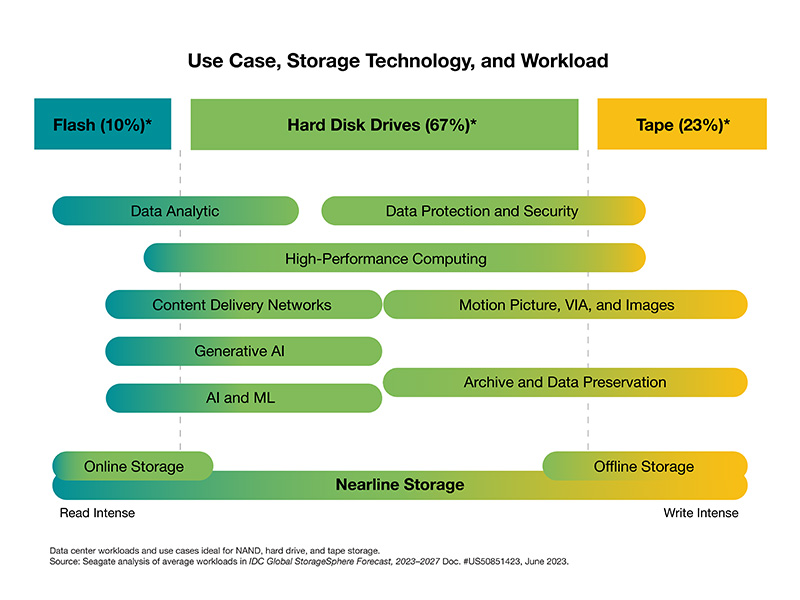
Second, TCO considerations are key to most data center infrastructure decisions. This forces a balance of cost, capacity, and performance. Optimal TCO is achieved by aligning the most cost-effective media—hard drive, flash, or tape—to the workload requirement. Hard drives and hybrid arrays (built from hard drives and SSDs) are a great fit for most enterprise and cloud storage and application use cases.
While flash storage excels in read-intensive scenarios, its endurance diminishes with increased write activity. Manufacturers address this with error correction and overprovisioning—extra, unseen storage, to replace worn cells. However, overprovisioning greatly increases the imbedded product cost and constant power is needed to avoid data loss, posing cost challenges in data centers.
Additionally, while technologies like triple level cell (TLC) and quad-level cell (QLC) allow flash to handle data-heavy workloads like hard drives, the economic rationale weakens for larger data sets or long-term retention. In these cases, disk drives, with their growing areal density, offer a more cost-effective solution.
Third, the claim that using an AFA is “simpler” than adopting a mix of media types in a tiered architecture is a solution in search of a problem.
Many hybrid storage systems employ a well-proven and finely tuned software-defined architecture that seamlessly integrates and harnesses the strengths of diverse media types into singular units. In scale-out private or public cloud data center architectures, file systems or software defined storage is used to manage the data storage workloads across data center locations and regions. AFAs and SSDs are a great fit for high-performance, read-intensive workloads. But it’s a mistake to extrapolate from niche use cases or small-scale deployments to the mass market and hyperscale where AFAs provide an unnecessarily expensive way to do what hard drives already deliver at a much lower TCO.
In some cases, all-flash systems are not even required at all as part of the highest performance solutions. There are hybrid storage systems that perform as well as or faster than all-flash.
Second, TCO considerations are key to most data center infrastructure decisions. This forces a balance of cost, capacity, and performance. Optimal TCO is achieved by aligning the most cost-effective media—hard drive, flash, or tape—to the workload requirement. Hard drives and hybrid arrays (built from hard drives and SSDs) are a great fit for most enterprise and cloud storage and application use cases.
While flash storage excels in read-intensive scenarios, its endurance diminishes with increased write activity. Manufacturers address this with error correction and overprovisioning—extra, unseen storage, to replace worn cells. However, overprovisioning greatly increases the imbedded product cost and constant power is needed to avoid data loss, posing cost challenges in data centers.
Additionally, while technologies like triple level cell (TLC) and quad-level cell (QLC) allow flash to handle data-heavy workloads like hard drives, the economic rationale weakens for larger data sets or long-term retention. In these cases, disk drives, with their growing areal density, offer a more cost-effective solution.
Third, the claim that using an AFA is “simpler” than adopting a mix of media types in a tiered architecture is a solution in search of a problem.
Many hybrid storage systems employ a well-proven and finely tuned software-defined architecture that seamlessly integrates and harnesses the strengths of diverse media types into singular units. In scale-out private or public cloud data center architectures, file systems or software defined storage is used to manage the data storage workloads across data center locations and regions. AFAs and SSDs are a great fit for high-performance, read-intensive workloads. But it’s a mistake to extrapolate from niche use cases or small-scale deployments to the mass market and hyperscale where AFAs provide an unnecessarily expensive way to do what hard drives already deliver at a much lower TCO.
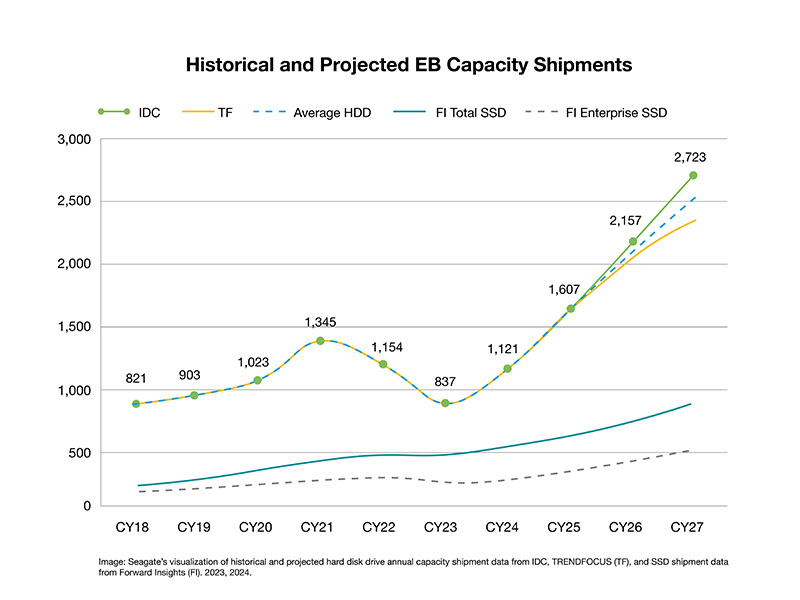
 The data bears it out. Analysis of data from IDC and TRENDFOCUS predicts an almost 250% increase in EB outlook for hard drives by 2028. Extrapolating further out in time, that ratio holds well into the next decade.
The data bears it out. Analysis of data from IDC and TRENDFOCUS predicts an almost 250% increase in EB outlook for hard drives by 2028. Extrapolating further out in time, that ratio holds well into the next decade.
 Hard drives, indeed, are here to stay—in synergy with flash storage. And the continued use of hard drives and hybrid array solutions supports, in turn, the continued use of SAS technologies in the infrastructure data centers.
About the Author
Jason Feist is senior vice president of marketing, products and markets, at Seagate Technology.
Hard drives, indeed, are here to stay—in synergy with flash storage. And the continued use of hard drives and hybrid array solutions supports, in turn, the continued use of SAS technologies in the infrastructure data centers.
About the Author
Jason Feist is senior vice president of marketing, products and markets, at Seagate Technology.


 , and Ultra Ethernet, and more.
“We’re excited to welcome executives, architects, developers, implementers, and users to our 12th annual Summit,” said David McIntyre, Compute, Memory, and Storage Summit Chair and member of the SNIA Board of Directors. “Our event features technology leaders from companies like Dell, IBM, Intel, Meta, Samsung – and many more – to bring us the latest developments in AI, compute, memory, storage, and security in our
, and Ultra Ethernet, and more.
“We’re excited to welcome executives, architects, developers, implementers, and users to our 12th annual Summit,” said David McIntyre, Compute, Memory, and Storage Summit Chair and member of the SNIA Board of Directors. “Our event features technology leaders from companies like Dell, IBM, Intel, Meta, Samsung – and many more – to bring us the latest developments in AI, compute, memory, storage, and security in our
Leave a Reply