








 We are increasingly living in a multi-cloud world, with potentially multiple private, public and hybrid cloud implementations supporting a single enterprise. Organizations want to leverage the agility of public cloud resources to run existing workloads without having to re-plumb or re-architect them and their processes. In many cases, applications and data have been moved individually to the public cloud. Over time, some applications and data might need to be moved back on premises, or moved partially or entirely, from one cloud to another.
That means simplifying the movement of data from cloud to cloud. Data movement and data liberation – the seamless transfer of data from one cloud to another – has become a major requirement.
On August 7, 2018, the SNIA Cloud Storage Technologies Initiative will tackle this issue in a live webcast, “Cloud Mobility and Data Movement.” We will explore some of these data movement and mobility issues and include real-world examples from the University of Michigan. We’ll discus:
We are increasingly living in a multi-cloud world, with potentially multiple private, public and hybrid cloud implementations supporting a single enterprise. Organizations want to leverage the agility of public cloud resources to run existing workloads without having to re-plumb or re-architect them and their processes. In many cases, applications and data have been moved individually to the public cloud. Over time, some applications and data might need to be moved back on premises, or moved partially or entirely, from one cloud to another.
That means simplifying the movement of data from cloud to cloud. Data movement and data liberation – the seamless transfer of data from one cloud to another – has become a major requirement.
On August 7, 2018, the SNIA Cloud Storage Technologies Initiative will tackle this issue in a live webcast, “Cloud Mobility and Data Movement.” We will explore some of these data movement and mobility issues and include real-world examples from the University of Michigan. We’ll discus:
- How do we secure data both at-rest and in-transit?
- Why is data so hard to move? What cloud processes and interfaces should we use to make data movement easier?
- How should we organize our data to simplify its mobility? Should we use block, file or object technologies?
- Should the application of the data influence how (and even if) we move the data?
- How can data in the cloud be leveraged for multiple use cases?
 The
The  These nine areas of focus are each actively supported by formed and functioning Technical Work Groups. Individuals from all facets of IT dedicate themselves to programs that unite the storage industry with the purpose of taking our technology to the next level.
As the Executive Director for SNIA, I find the future of storage to be promising and exciting! We’re in the middle of historical transformation and innovation – and SNIA is center stage for a brave new world of storage. Data is being generated at unprecedented rates…and accelerating still…technology has to change to support the new business models of today and tomorrow. When I look at the strong history, and the robust technical focus of the organization and its members today, I know that together we can write a very bright future for the industry and the world. So join us in this dynamic journey to the next big discovery and fundamental technologies that are the basis for recording and saving the world’s history and humanity’s memories.
Sincerely,
Michael Oros, Executive Director of the Storage Networking Industry Association
These nine areas of focus are each actively supported by formed and functioning Technical Work Groups. Individuals from all facets of IT dedicate themselves to programs that unite the storage industry with the purpose of taking our technology to the next level.
As the Executive Director for SNIA, I find the future of storage to be promising and exciting! We’re in the middle of historical transformation and innovation – and SNIA is center stage for a brave new world of storage. Data is being generated at unprecedented rates…and accelerating still…technology has to change to support the new business models of today and tomorrow. When I look at the strong history, and the robust technical focus of the organization and its members today, I know that together we can write a very bright future for the industry and the world. So join us in this dynamic journey to the next big discovery and fundamental technologies that are the basis for recording and saving the world’s history and humanity’s memories.
Sincerely,
Michael Oros, Executive Director of the Storage Networking Industry Association
 is in the process of standardizing a TCP transport. It will be called NVMe over TCP (NVMe
is in the process of standardizing a TCP transport. It will be called NVMe over TCP (NVMe In April 2016, the European Union (EU) approved a new law called the General Data Protection Regulation (GDPR). This coming May 25th, however, is the start of enforcement, meaning that any out-of-compliance organization that does business in the EU could face large fines. Some companies are choosing to not conduct business in the EU as a result, including
In April 2016, the European Union (EU) approved a new law called the General Data Protection Regulation (GDPR). This coming May 25th, however, is the start of enforcement, meaning that any out-of-compliance organization that does business in the EU could face large fines. Some companies are choosing to not conduct business in the EU as a result, including 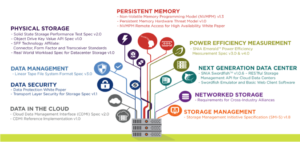
Leave a Reply