







Hyperscale and enterprise data centers continue to grow rapidly and to use SAS products as a backbone. Why SAS, and what specific SAS products are helping these data centers to grow? This article briefly discusses the technology evolution of SAS, bringing us to our latest generation of 24G SAS. We will examine recent market data from TRENDFOCUS, underscoring the established and growing trajectory of SAS products. We will highlight our latest plugfest, which smoothed the way for 24G SAS to seamlessly enter the existing data storage ecosystem. Finally, we will help the reader to understand the availability, breadth, and depth of 24G SAS products that are available today, and where you can get those products.
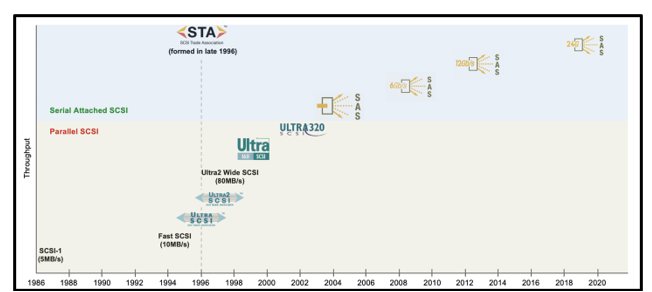
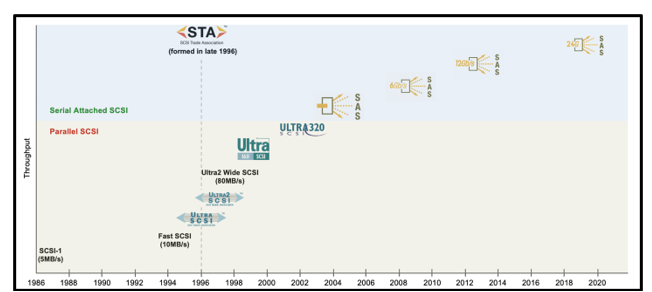
24G SAS: Naturally Evolving from A Long Line of SCSI
The first generation of the parallel SCSI interface, known as SCSI-1, was introduced in 1986 at 5MB/s. Subsequent generations of SCSI followed, effectively doubling the bandwidth each time. The SCSI Trade Association was formed in 1996 and began marketing efforts to promote SCSI technology and its use in enterprise deployments. Ultra640 SCSI was discussed in the early 2000s, but cable lengths became impractical at those data rates. That pushed the industry to transition to a serial version of the technology, with the first Serial Attached SCSI (SAS) generation being introduced in 2004 at 3Gb/s.
Let’s fast forward to today. Leveraging the SAS-4 spec, 24G SAS is the latest generation to hit the market, increasing data rates to a maximum of 24Gb/s. With close to thirty years’ worth of products installed throughout global data centers, customers want to keep their current infrastructure while scaling up for more throughput. SAS continues to be a widely used interface for storage in hyperscale and enterprise data centers.
SAS Continues to Be Deployed: The Data Analysts Weigh In
Data storage industry’s market research and consulting firm TRENDFOCUS has shown us the industry numbers that support our trade association’s assertions that SAS market continues to grow. “SAS will remain the storage infrastructure of choice in the enterprise market,” said Don Jeanette, Vice President of data storage market research firm TRENDFOCUS. “With SAS’ entrenched presence throughout data centers, it is key for STA and its member companies to continue to support this existing infrastructure while developing for the future.”
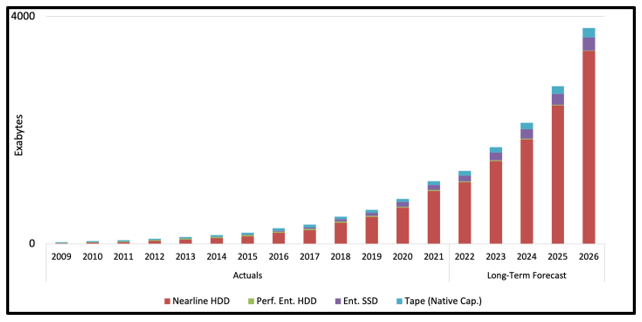
Fig. 2: Enterprise Storage Capacity (by Technology)
Source: TRENDFOCUS, January 2023
Industry Plugfests Keep Products Playing Together
As discussed earlier, SAS technology has increased in speed and features over many years, while maintaining its essential industry-wide compatibility. To help that happen, STA has conducted nineteen different multi-day test events, called “plugfests,” to guarantee SAS interoperability across vendors and the ecosystem.
The second 24G SAS plugfest was held in late 2021. These events are typically a logistical challenge with new technology, products, engineers, and other personnel coming together to make sure products work together before they go out to the market. This plugfest was especially challenging in the recently post-global pandemic environment with many companies skittish to commit personnel to travel.
STA overcame this hurdle by holding a hybrid format at two locations at member company facilities (Broadcom and Microchip), while maintaining credibility and authenticity with independent auditing of test results by University of New Hampshire InterOperability Laboratory (UNH-IOL). The test event included participation by 10 diverse companies, both STA member companies and non-member companies, representing all the different pieces of infrastructure to make a complete SAS network.
As the number of new 24G SAS products available in the market continued to increase, completion of this STA plugfest was another proof point to show 24G SAS ecosystem maturing. The vendor product interoperability testing demonstrated SAS is a reliable choice, giving confidence to buyers about continued reliability and support. Featured were active optical cables included in the testing, demonstrating the SAS interface may reach much longer distances beyond those afforded by passive copper cables.
The 2021 plugfest had an aggressive list of activities to accomplish. Engineers at the test facilities checked off:
- Interoperability of 24G SAS products in a realistic working environment of the standard as specified.
- In-depth testing of both the SAS-4 and SPL-4 protocol and electrical specifications.
- Successful interoperability testing with packetization.
- Testing of passive cables with lengths up to 6 meters, active optical cables with lengths up to 100 meters, and various interconnects and backplanes, including:
-
- multiple vendor cables and interconnects
- long and short channels
- cable EEPROM identification/access
- Mini SAS HD and SlimSAS 24G connectors
24G SAS Products: Available Now & Working for You
Today, end users can choose from a wide array of 24G SAS products on the market. All parts of the data storage ecosystem are available to end users, from storage devices to the necessary connecting products. In this section, we will highlight availability of 24G SAS products from several of our STA member companies.
Broadcom, a STA Principal Member company, is a global technology leader that designs, develops and supplies a broad range of semiconductor and infrastructure software solutions. As such, they offer a wide range of SAS products, from SAS expanders to HBAs to RAID-on-a-Chip solutions. Broadcom’s 24G SAS products were featured at STA’s 2022 Flash Memory Summit booth in a live demo, giving our booth visitors an opportunity to see the technology up close. Here are direct links to many of their 24G SAS products available now:
- 9600 Storage Family
- 24G SAS Expanders
KIOXIA America, Inc. also a STA Principal Member, is the U.S.-based subsidiary of KIOXIA Corporation, a leading worldwide supplier of flash memory and solid-state drives (SSDs). KIOXIA SSDs were also in STA’s 2022 Flash Memory Summit booth in the live demo, giving our booth visitors an opportunity to see SAS SSDs. Thanks to SAS’ backward compatibility, end users can mix KIOXIA’s 12Gb/s SAS and 24G SAS SSDs in the same system. Here are direct links to SSDs available today, that will work in a 24G SAS environment:
- PM7 Series 24G Enterprise SAS SSD
- PM6 Series 24G Enterprise SAS SSD
- RM6 Series 12Gb/s Value SAS SSD (Dell)
- RM6 Series 12Gb/s Value SAS SSD (HPE)
Samsung Semiconductor is also a STA Principal Member who provides innovative semiconductor solutions, including DRAM, SSD, processors, image sensors with a wide-ranging portfolio of trending technologies. Samsung announced the launch of their 24G SAS SSD in 2021, and product details and link are here:
PM1653 is Samsung’s 24G SAS SSD, and is optimized for next-generation server and storage applications. The PM1653 is the first Samsung SSD to support the 24G SAS interface. This allows it to offer up to twice the performance of previous 12Gb/s SAS SSDs. Dual ports ensure greater reliability, while Samsung’s sixth-generation, 128-layer V-NAND enables capacities as high as 30.72TB. The PM1653’s 24G SAS support streamlines storage infrastructure by maximizing throughput. This is possible thanks to the addition of a cutting-edge Rhino controller that doubles the PM1653’s bandwidth. This allows it to offer roughly twice the performance and more than double the random speeds of the previous generation.
Seagate, a STA Principal Member, is a global technology leader for nearly 45 years and has shipped almost four billion terabytes of data capacity. Their 12Gb/s SAS and 6G SATA Enterprise HDDs both work in the SAS infrastructure for greater flexibility for enterprise data systems. They have a wide range of HDDs in their Exos E Series Hard Drives to fulfill the needs of the SAS user. Seagate says, always on and always working, the Exos E series of hard drives is loaded with advanced options for optimal performance, reliability, security and user-definable storage management. Built on generations of industry-defining innovation, Exos E is designed to work and perform consistently in enterprise-class workloads.
Teledyne LeCroy is a STA Promotional Member and a leading manufacturer of advanced oscilloscopes, protocol analyzers, and other test instruments that verify performance, validate compliance, and debug complex electronic systems quickly and thoroughly. Their participation in our many interoperability test events has helped pave the way for SAS’ continual smooth introduction into the marketplace, generation after generation. They offer protocol analyzers specifically for 24G SAS products:
- The Sierra T244 is a SAS 4.0 protocol analyzer designed to non-intrusively capture up to four 24 Gb/s SAS logical links providing unmatched analysis and debug capabilities for developers working on next generation storage systems, devices and software.
- The Sierra M244 is the industry’s first SAS 4.0 protocol analyzer / jammer / exerciser system for testing next generation storage systems, devices and software.
- Austin Labs Testing & Training provides a four-day comprehensive SAS protocol training course covering 24G SAS, legacy data rates, and includes hands-on lab time for each protocol class. Along with training there are also options for testing and analysis for SAS products.
In addition to our member companies, many other companies manufacture, market, and sell 24G SAS products today. The below figure shows a range of companies who are making and selling 24G SAS products right now.
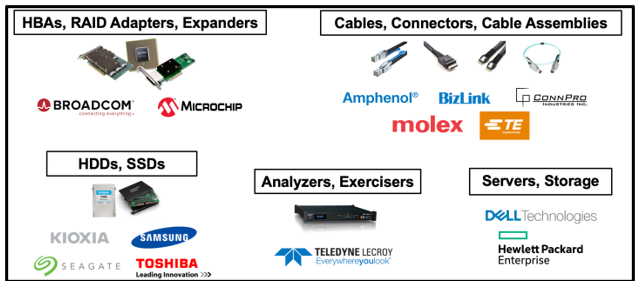
Fig. 3: A Sampling of Companies Providing 24G SAS Products Today
Learn More about SAS, and Stay Informed
Thanks to the efforts of the STA and the T10 Technical Committee, Serial Attached SCSI continues to evolve to meet market needs. Stay abreast of SAS latest technology developments by watching free STA webcasts and other educational videos on the organization’s YouTube channel and follow our social media channels on LinkedIn and Twitter. To find links to all of these and more, visit the STA web site at http://www.scsita.org.


 , and UCIe
, and UCIe


 Summit topics include Memory’s Headed for Change, High Performance Data Analytics, CXL 3.0, Detecting Ransomware, Meeting Scaling Challenges, Open Standards for Innovation at the Package Level, and Standardizing Memory to Memory Data Movement. Great panel discussions are on tap as well. Kurt Lender of the CXL Consortium will lead a discussion on Exploring the CXL Device Ecosystem and Usage Models, Dave Eggleston of Microchip will lead a panel with Samsung and SMART Modular on Persistent Memory Trends, and Cameron Brett of KIOXIA will lead a SSD Form Factors Update. More details at
Summit topics include Memory’s Headed for Change, High Performance Data Analytics, CXL 3.0, Detecting Ransomware, Meeting Scaling Challenges, Open Standards for Innovation at the Package Level, and Standardizing Memory to Memory Data Movement. Great panel discussions are on tap as well. Kurt Lender of the CXL Consortium will lead a discussion on Exploring the CXL Device Ecosystem and Usage Models, Dave Eggleston of Microchip will lead a panel with Samsung and SMART Modular on Persistent Memory Trends, and Cameron Brett of KIOXIA will lead a SSD Form Factors Update. More details at 

 Consortium too?
A. While we have not communicated with the Compute Express
Link (CXL) Consortium formally. There have been a few conversations with CXL
interested parties. We will need to engage in discussions with CXL Consortium
like we have with SNIA, DASH, and others.
Q. Can you elaborate on the purpose of APIs for AI/ML?
A. The DPU solutions contain accelerators
and capabilities that can be leveraged by AI/ML type solutions, and we will
need to consider what APIs need to be exposed to take advantage of these
capabilities. OPI believes there is a set of data movement and co-processor
APIs to support DPU incorporation into AI/ML solutions. In keeping with its
core mission, OPI is not going to attempt to redefine the existing core AI/ML
APIs. We may look at how to incorporate those into DPUs directly as well.
Q. Have you considered creating a TEE (Trusted Execution
Environment) oriented API?
A. This is something that has been considered and is a
possibility in the future. There are some different sides to this:
1) OPI itself using TEE on the
DPU. This may be interesting, although we’d need a compelling use case.
2) Enabling OPI users to utilize
the TEE via a vendor neutral interface. This will likely be interesting, but
potentially challenging for DPUs as OPI is considering them. We are
currently focused on enabling applications running in containers on DPUs and
securing containers via TEE is currently a research area in the industry. For example,
there is this project at the “sandbox” maturity level:
Consortium too?
A. While we have not communicated with the Compute Express
Link (CXL) Consortium formally. There have been a few conversations with CXL
interested parties. We will need to engage in discussions with CXL Consortium
like we have with SNIA, DASH, and others.
Q. Can you elaborate on the purpose of APIs for AI/ML?
A. The DPU solutions contain accelerators
and capabilities that can be leveraged by AI/ML type solutions, and we will
need to consider what APIs need to be exposed to take advantage of these
capabilities. OPI believes there is a set of data movement and co-processor
APIs to support DPU incorporation into AI/ML solutions. In keeping with its
core mission, OPI is not going to attempt to redefine the existing core AI/ML
APIs. We may look at how to incorporate those into DPUs directly as well.
Q. Have you considered creating a TEE (Trusted Execution
Environment) oriented API?
A. This is something that has been considered and is a
possibility in the future. There are some different sides to this:
1) OPI itself using TEE on the
DPU. This may be interesting, although we’d need a compelling use case.
2) Enabling OPI users to utilize
the TEE via a vendor neutral interface. This will likely be interesting, but
potentially challenging for DPUs as OPI is considering them. We are
currently focused on enabling applications running in containers on DPUs and
securing containers via TEE is currently a research area in the industry. For example,
there is this project at the “sandbox” maturity level:
Leave a Reply