








The SNIA Cloud Storage Initiative hosted a live Webcast “Cloud Object Storage 101.” Like any "101" type course, there were a lot of good questions. Here they all are - with our answers. If you have additional questions, please let us know by commenting on this blog.
Q. How do you envision the new role of tape (LTO) in this unstructured data growth?
A. Exactly the same way that tape has always played a part; it’s the storage medium that requires no power to store cold data and is cheap per bit. Although it has a limited shelf life, and although we believe that flash will eventually replace it, it still has a secure & growing foreseeable future.
Q. What are your thoughts on whether object storage can exist outside the bounds of supporting file systems? Block devices directly storing objects using the key as reference and removing the intervening file system? A hierarchy of objects instead of files?
A. All of these things. Objects can be objects identified by an ID in a flat non-hierarchical structure; or we can impose a hierarchy by key- to objectID translation; or indeed, an object may contain complete file systems or be treated like a block device. There are really no restrictions on how we can build meta data that describes all these things over the bytes of storage that makes up an object.
Q. Can you run write insensitive low latency apps on object storage, ex: virtual machines?
A. Yes. Object storage can be made up of the same stuff as other high performance storage systems; for instance, flash connect via high bandwidth and low latency networks. Or they could even be object stores built over PCIe and NVDIMM.
Q. Is erasure coding (EC) expensive in terms of networking and resources utilization (especially in case of rebuild)?
A. No, that’s one of the advantages of EC. Rebuilds take place by reading data from many disks and writing it to many disks; in traditional RAID rebuilds, the focus is normally on the one disk that’s being rebuilt.
Q. Is there any overhead for small files or object use cases? Do you have a recommended size?
A. Each system will have its own advantages and disadvantages for objects of specific sizes. In general, object stores are designed to store billions of objects, so the number of objects is usually not an issue.
Q. Can you comment on Internet bandwidth limitations on geographically dispersed erasure coded data?
A. Smart caching can make a big difference, but at the end of the day, a geographically EC dispersed object store won’t be faster than a local store. You can’t beat the speed of light.
Q. The suppliers all claim easy exit strategies from their systems. If we were to use one of the on-premise solutions such as ECS or Cleversafe, and then down the road decide to move off-premise, is the migration/egress typically as easy as claimed?
A. In general, any proprietary interface might lock you in. The SNIA’s CDMI is vendor neutral, and supported by a number of vendors. Amazon’s S3 is a popular and common interface. Ultimately, vendors want your data on their systems – and that means making it easy to get the data from a competing vendor’s system; lock-in is not what vendors want. Talk to your vendor and ask for other users’ experiences to get confirmation of their claims.
Q. Based on factual information, where are you seeing the most common use cases for Object Storage?
A. There are many, and each vendor of cloud storage has particular markets. Backup is a common case, as are systems in the healthcare space that treat data such as scans and X-rays as objects.
Q. NAS filers only scale up not out. They are hard to manage at scale. Why use them anymore?
A. There are many NAS systems that scale out as well as up. NFSv4 support high degrees of scale out and there are file systems like Gluster that provide very large-scale solutions indeed, into the multi-petabyte range.
Q. Are there any specific uses cases to avoid when considering object storage?
A. Yes. Many legacy applications will not generate any savings or gains if moved to object storage.
Q. Would you agree with industry statements that 80% of all data written today will NEVER be accessed again; and that we just don't know WHICH 20% will be read again?
A. Yes to the first part, and no to the second. Knowing which 80% is cold is the trick. The industry is developing smart ways of analyzing data to help with the issue of ensuring cached data is hot data, and that cold data is placed correctly first time around.
Q. Is there also the possibility to bring "compliance" in the object storage? (thinking about banking, medical and other sensible data that needs to be tracked, retention, etc...)
A. Yes. Many object storage vendors provide software to do this.
The SNIA Cloud Storage Initiative hosted a live Webcast “Cloud Object Storage 101.” Like any “101” type course, there were a lot of good questions. Here they all are – with our answers. If you have additional questions, please let us know by commenting on this blog.
Q. How do you envision the new role of tape (LTO) in this unstructured data growth?
A. Exactly the same way that tape has always played a part; it’s the storage medium that requires no power to store cold data and is cheap per bit. Although it has a limited shelf life, and although we believe that flash will eventually replace it, it still has a secure & growing foreseeable future.
Q. What are your thoughts on whether object storage can exist outside the bounds of supporting file systems? Block devices directly storing objects using the key as reference and removing the intervening file system? A hierarchy of objects instead of files?
A. All of these things. Objects can be objects identified by an ID in a flat non-hierarchical structure; or we can impose a hierarchy by key- to objectID translation; or indeed, an object may contain complete file systems or be treated like a block device. There are really no restrictions on how we can build meta data that describes all these things over the bytes of storage that makes up an object.
Q. Can you run write insensitive low latency apps on object storage, ex: virtual machines?
A. Yes. Object storage can be made up of the same stuff as other high performance storage systems; for instance, flash connect via high bandwidth and low latency networks. Or they could even be object stores built over PCIe and NVDIMM.
Q. Is erasure coding (EC) expensive in terms of networking and resources utilization (especially in case of rebuild)?
A. No, that’s one of the advantages of EC. Rebuilds take place by reading data from many disks and writing it to many disks; in traditional RAID rebuilds, the focus is normally on the one disk that’s being rebuilt.
Q. Is there any overhead for small files or object use cases? Do you have a recommended size?
A. Each system will have its own advantages and disadvantages for objects of specific sizes. In general, object stores are designed to store billions of objects, so the number of objects is usually not an issue.
Q. Can you comment on Internet bandwidth limitations on geographically dispersed erasure coded data?
A. Smart caching can make a big difference, but at the end of the day, a geographically EC dispersed object store won’t be faster than a local store. You can’t beat the speed of light.
Q. The suppliers all claim easy exit strategies from their systems. If we were to use one of the on-premise solutions such as ECS or Cleversafe, and then down the road decide to move off-premise, is the migration/egress typically as easy as claimed?
A. In general, any proprietary interface might lock you in. The SNIA’s CDMI is vendor neutral, and supported by a number of vendors. Amazon’s S3 is a popular and common interface. Ultimately, vendors want your data on their systems – and that means making it easy to get the data from a competing vendor’s system; lock-in is not what vendors want. Talk to your vendor and ask for other users’ experiences to get confirmation of their claims.
Q. Based on factual information, where are you seeing the most common use cases for Object Storage?
A. There are many, and each vendor of cloud storage has particular markets. Backup is a common case, as are systems in the healthcare space that treat data such as scans and X-rays as objects.
Q. NAS filers only scale up not out. They are hard to manage at scale. Why use them anymore?
A. There are many NAS systems that scale out as well as up. NFSv4 support high degrees of scale out and there are file systems like Gluster that provide very large-scale solutions indeed, into the multi-petabyte range.
Q. Are there any specific uses cases to avoid when considering object storage?
A. Yes. Many legacy applications will not generate any savings or gains if moved to object storage.
Q. Would you agree with industry statements that 80% of all data written today will NEVER be accessed again; and that we just don’t know WHICH 20% will be read again?
A. Yes to the first part, and no to the second. Knowing which 80% is cold is the trick. The industry is developing smart ways of analyzing data to help with the issue of ensuring cached data is hot data, and that cold data is placed correctly first time around.
Q. Is there also the possibility to bring “compliance” in the object storage? (thinking about banking, medical and other sensible data that needs to be tracked, retention, etc…)
A. Yes. Many object storage vendors provide software to do this.
 , and many more.
Check out our lineup of keynote speakers - they'll inspire you with their journeys! Dan Maslowski, Global Engineering Head at Citigroup CATE,will lead us on a dive down the software-defined storage rabbit hole to define cloud architecture in the data center. Gary Grider, HPC Director at the Los Alamos National Labs, will take us on a "Data Lake" cruise, and how to navigate requirements for long-term retention of mostly cold data. And Stephen Bates, Technical Director at Microsemi, will steer us on the Persistent Memory path, with the stones to step on and the boulders to avoid.
SDC also includes two plugfests. Participants at the Cloud Interoperability Plugfest will test the interoperability of well adopted cloud storage interfaces. We always have a large showing of CDMI implementations at this event, but are also looking for implementations of S3 and Swift (and Cinder/Manila) interfaces. You can register for the Cloud Plugfest
, and many more.
Check out our lineup of keynote speakers - they'll inspire you with their journeys! Dan Maslowski, Global Engineering Head at Citigroup CATE,will lead us on a dive down the software-defined storage rabbit hole to define cloud architecture in the data center. Gary Grider, HPC Director at the Los Alamos National Labs, will take us on a "Data Lake" cruise, and how to navigate requirements for long-term retention of mostly cold data. And Stephen Bates, Technical Director at Microsemi, will steer us on the Persistent Memory path, with the stones to step on and the boulders to avoid.
SDC also includes two plugfests. Participants at the Cloud Interoperability Plugfest will test the interoperability of well adopted cloud storage interfaces. We always have a large showing of CDMI implementations at this event, but are also looking for implementations of S3 and Swift (and Cinder/Manila) interfaces. You can register for the Cloud Plugfest  Mark Carlson is the current Chair of the SNIA Technical Council (TC). Mark has been a SNIA member and volunteer for over 18 years, and also wears many other SNIA hats. Recently, SNIA on Storage sat down with Mark to discuss his first nine months as the TC Chair and his views on the industry.
SNIA on Storage (SoS): Within SNIA, what is the most important activity of the SNIA Technical Council?
Mark Carlson (MC): The SNIA Technical Council works to coordinate and approve the technical work going on within SNIA. This includes both SNIA Architecture (standards) and SNIA Software. The work is conducted within 13 SNIA
Mark Carlson is the current Chair of the SNIA Technical Council (TC). Mark has been a SNIA member and volunteer for over 18 years, and also wears many other SNIA hats. Recently, SNIA on Storage sat down with Mark to discuss his first nine months as the TC Chair and his views on the industry.
SNIA on Storage (SoS): Within SNIA, what is the most important activity of the SNIA Technical Council?
Mark Carlson (MC): The SNIA Technical Council works to coordinate and approve the technical work going on within SNIA. This includes both SNIA Architecture (standards) and SNIA Software. The work is conducted within 13 SNIA  SoS: What has been your focus this first nine months of 2016?
MC: The SNIA Technical Council has overseen a major effort to integrate a new standard organization into SNIA. The creation of the new
SoS: What has been your focus this first nine months of 2016?
MC: The SNIA Technical Council has overseen a major effort to integrate a new standard organization into SNIA. The creation of the new 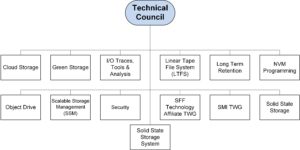 SoS: What's upcoming for the next six months?
MC: The TC is currently working on a white paper to address data center drive requirements and the features and existing interface standards that satisfy some of those requirements. Of course, not all the solutions to these requirements will come from SNIA, but we think SNIA is in a unique position to bring in the data center customers that need these new features and work with the drive vendors to prototype solutions that then make their way into other standards efforts. Features that are targeted at the NVM Express, T10, and T13 committees would be coordinated with these customers.
SoS: Can non-members get involved with SNIA?
MC: Until very recently, if a company wanted to contribute to a software project within SNIA, they had to become a member. This was limiting to the community, and cut off contributions from those who were using the code, so SNIA has developed a convenient
SoS: What's upcoming for the next six months?
MC: The TC is currently working on a white paper to address data center drive requirements and the features and existing interface standards that satisfy some of those requirements. Of course, not all the solutions to these requirements will come from SNIA, but we think SNIA is in a unique position to bring in the data center customers that need these new features and work with the drive vendors to prototype solutions that then make their way into other standards efforts. Features that are targeted at the NVM Express, T10, and T13 committees would be coordinated with these customers.
SoS: Can non-members get involved with SNIA?
MC: Until very recently, if a company wanted to contribute to a software project within SNIA, they had to become a member. This was limiting to the community, and cut off contributions from those who were using the code, so SNIA has developed a convenient 

Leave a Reply